
Жан-Батист Лальман (Jean Baptiste Lallement), директор по инжинирингу в компании Canonical, представил проект Myna, развивающий приложение распознавания речи, которое намерены использовать для организации голосового ввода и распознавания команд на естественном языке в Ubuntu Desktop. Проект распространяется под лицензией GPLv3, но в репозитории пока присутствуют только наброски с описанием модульной архитектуры проекта и его интеграции с Ubuntu. К выпуску Ubuntu 26.10 приложение планируют довести до пригодности к голосовому вводу текста. Сеанс работы с приложением сводится к активации через клавиатурную комбинацию, диктовки вслух и вставки распознанного текста в текущее приложение через симуляцию клавиатурного ввода по мере его произнесения. Во время включения микрофона в панели будет показываться специальный индикатор. В качестве базового тестируемого окружения заявлен GNOME на базе Wayland, но приложение изначально проектируется с расчётом возможности адаптации для различных сред рабочего стола. Для распознавания в Myna будет задействована AI-модель, выполняемая локально. Среди требований к приложению: возможность работы без подключения к интернету; включение микрофона только после явной активации режима диктовки горячей клавишей; обработка звука в памяти, очищаемой после каждого использования; запрет на передачу записей звука во внешние сервисы. Компоненты для распознавания речи, взаимодействия с пользователем, управления диктовкой и подстановки текста развиваются в форме модулей. Окружение для выполнения AI-моделей будет оформлено в виде snap-пакета. В качестве возможных моделей для распознавания упоминаются Wisper, Parakeet, NemoTron и Qwen3-ASR. Сервис управления диктовкой отслеживает нажатие горячей клавиши, активирует микрофон, обращается через API к AI-модели в snap-пакете, перенаправляет в неё звуковой поток из звукового сервиса и координирует потоки данных. Звуковой сервис обращается к звуковому устройству, как напрямую, так и через звуковые серверы PulseAudio или PipeWire, подавляет шум и выравнивает громкость. Генерируемый моделью текст передаётся в модуль постобработки для чистки, нормализации, форматирования и расстановки знаков препинания. Финальный текст подставляется в приложение через подстановку ввода, например, через Wayland-протокол input-method или IBus. После стабилизации начальной функциональности не исключается реализация таких возможностей, как работа в роли голосового ассистента, выполнение голосовых команд, голосовое управление рабочим столом и перевод диктуемого текста с автоматическим распознаванием языка.
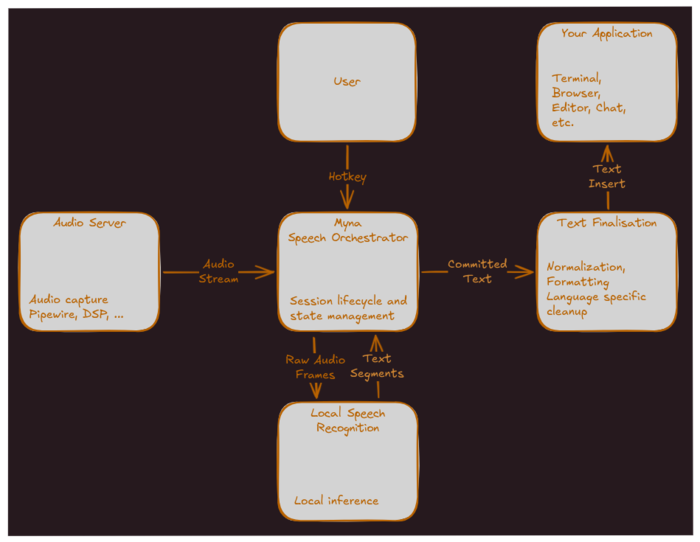
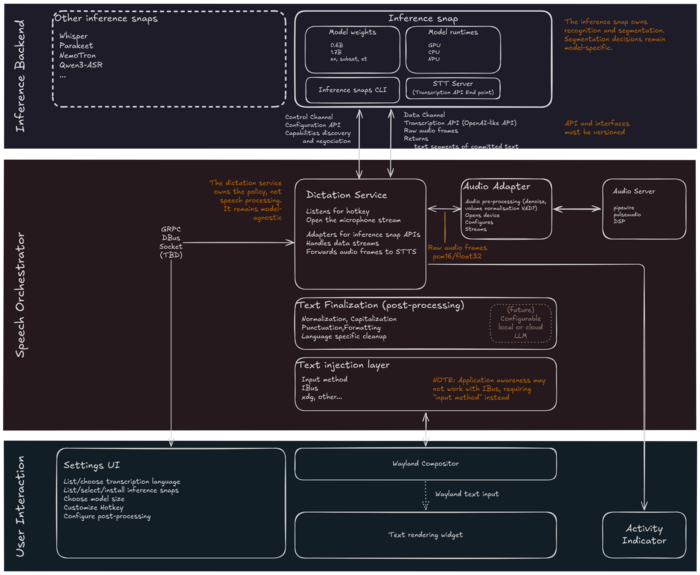
Источник: https://www.opennet.ru/opennews/art.shtml?num=65709
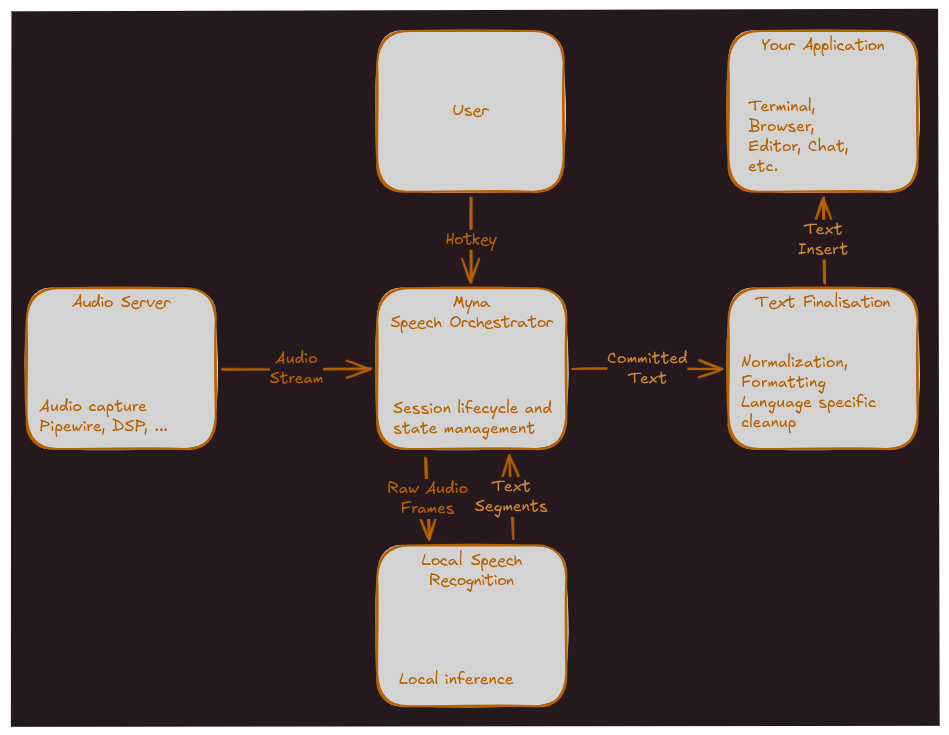
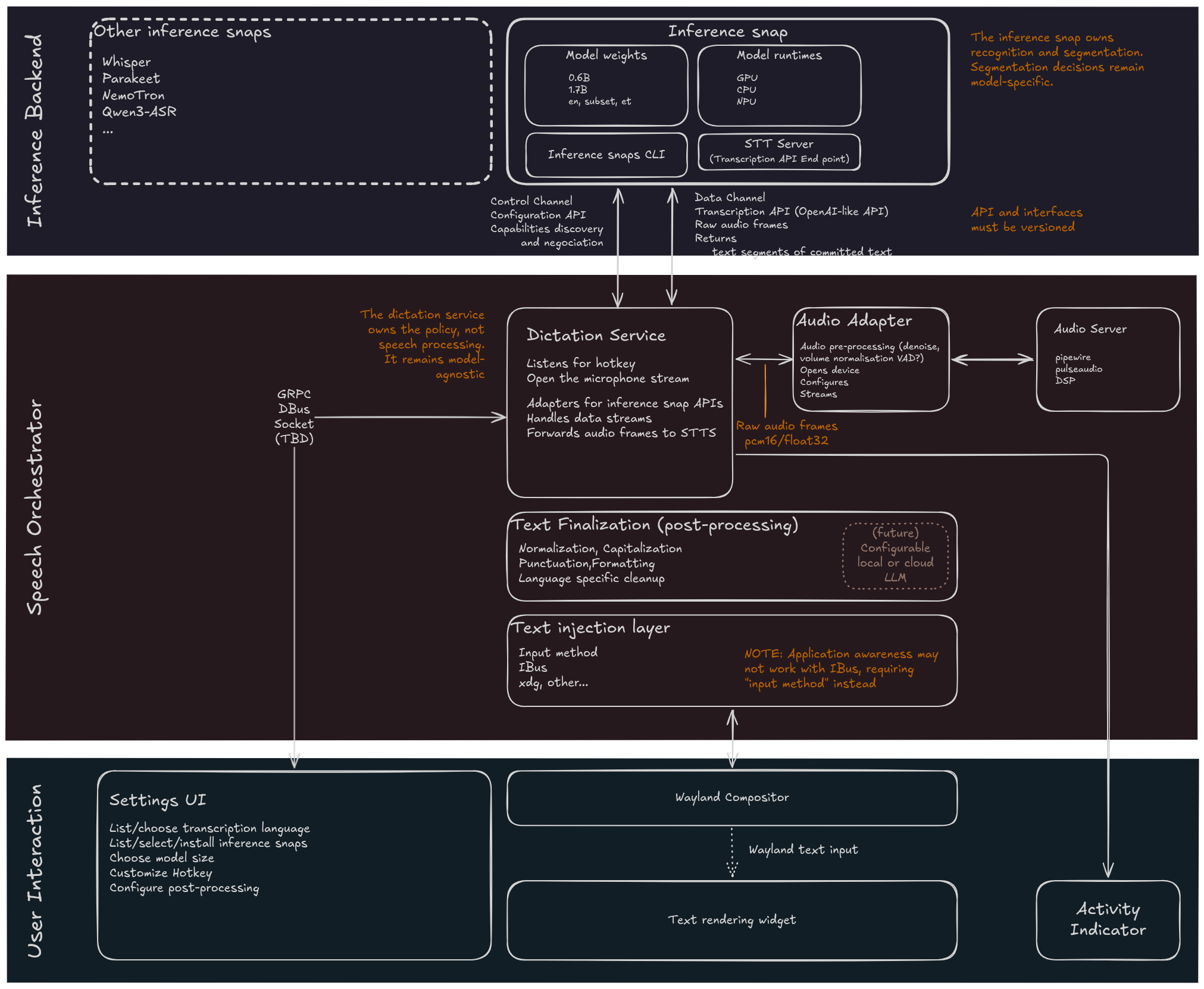
Источник: https://www.opennet.ru/opennews/art.shtml?num=65709